Technology Platforms
We don't just collect data — we build the infrastructure required to collect it at scale with zero compromise on quality.
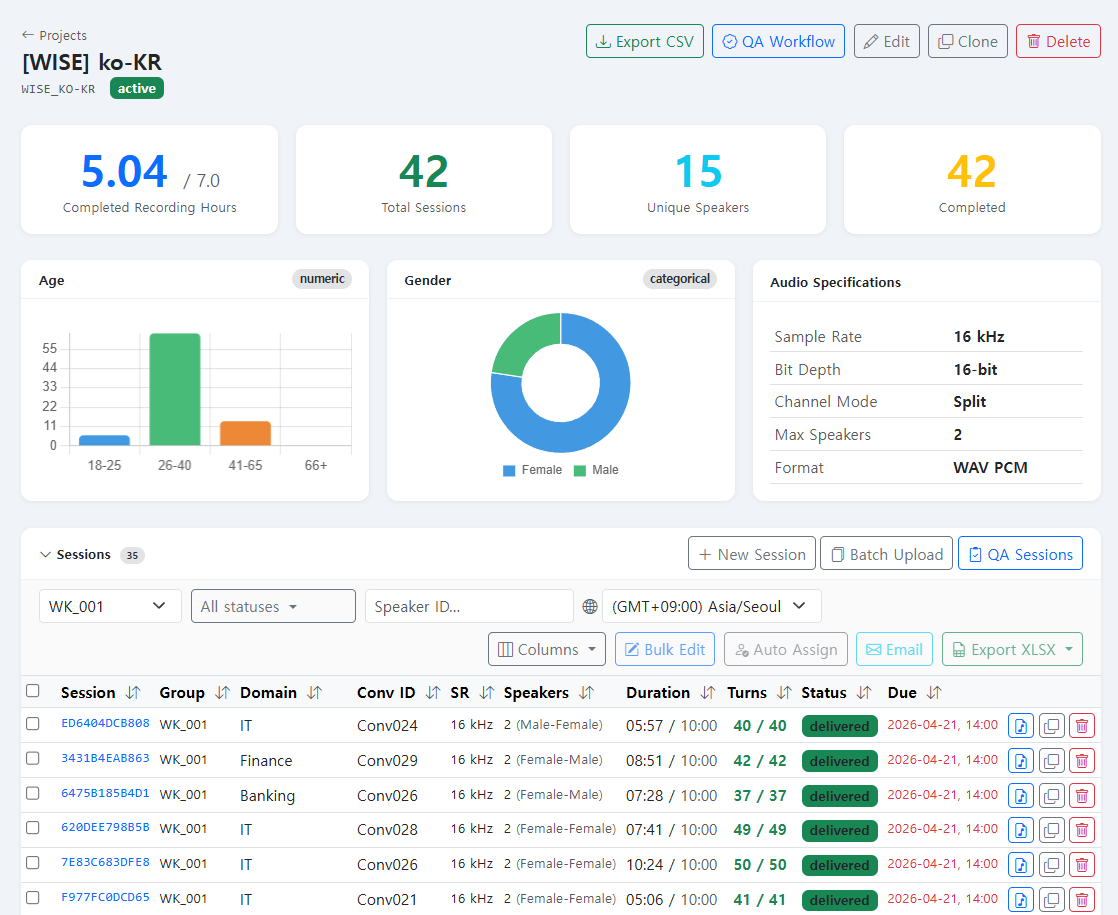
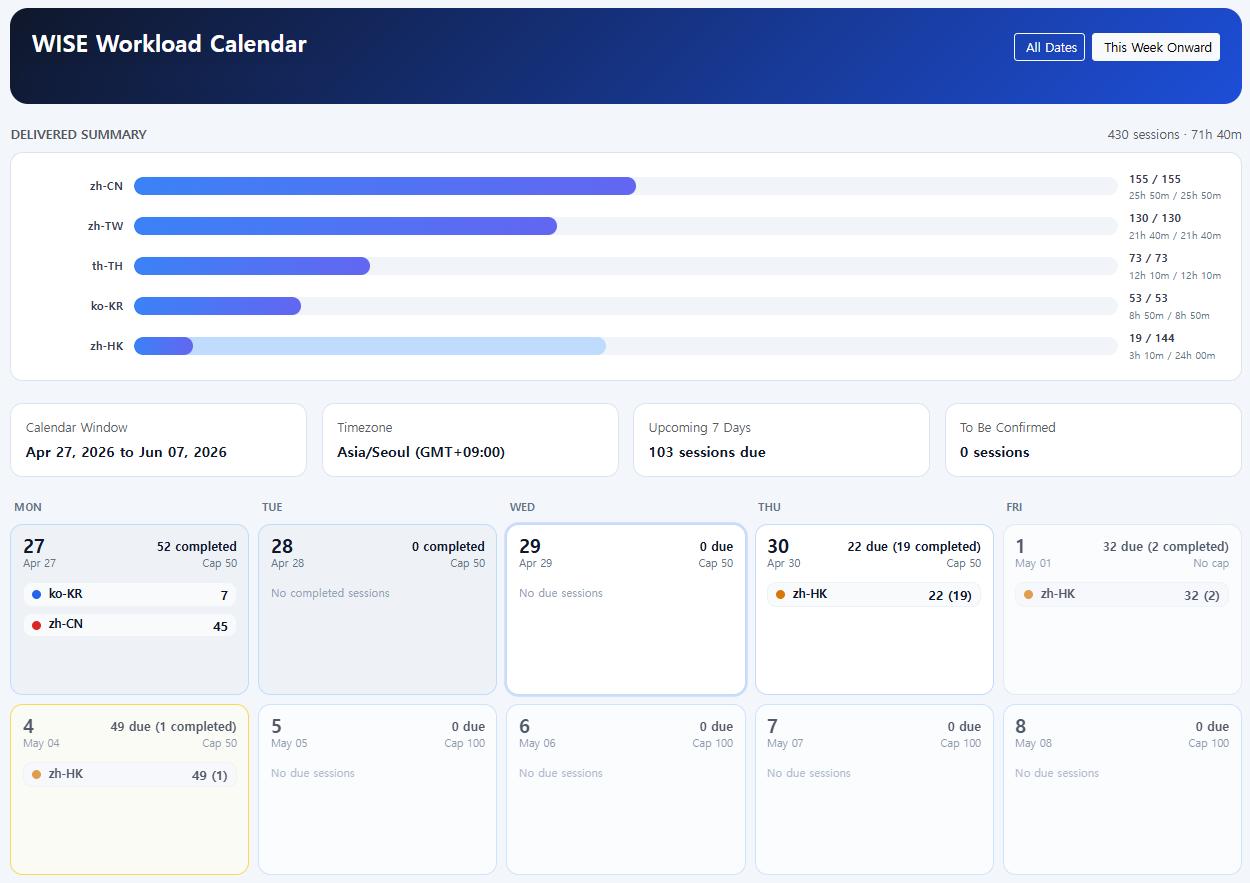
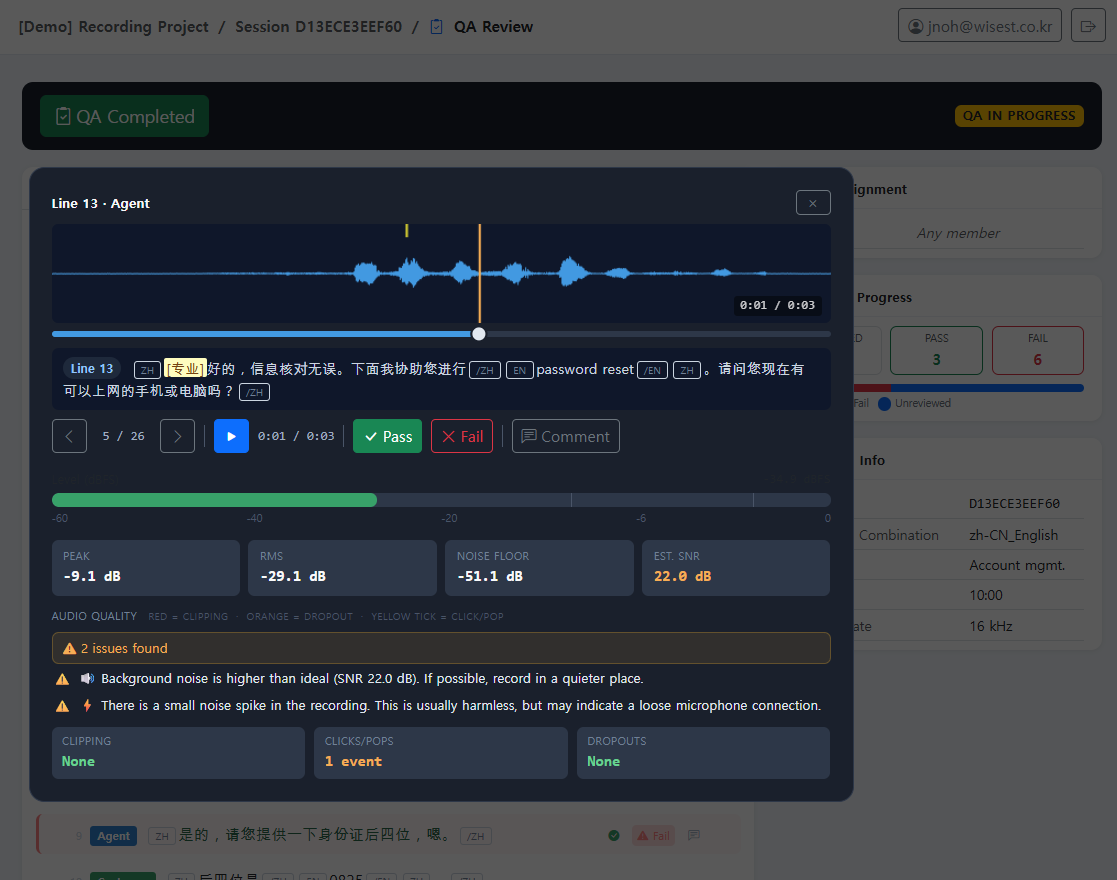
Professional-grade audio recording with real-time monitoring dashboards, automated technical QA for SNR and clipping detection, and flexible moderator-led or self-directed workflows — supporting multi-speaker sessions, multi-channel capture, and native 8 kHz recording via dedicated mobile plugins for telephony-grade datasets.
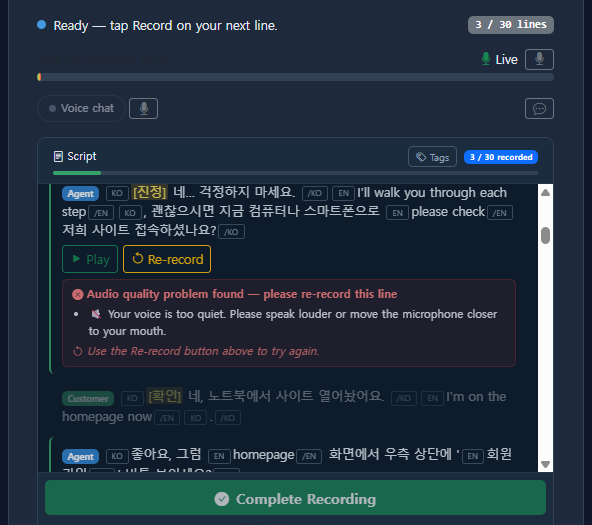
A hardened portal purpose-built for multilingual document collection. Features personal join links, built-in QA workflows, and robust file formatting validation — ensuring every submission meets specification before it enters the pipeline.
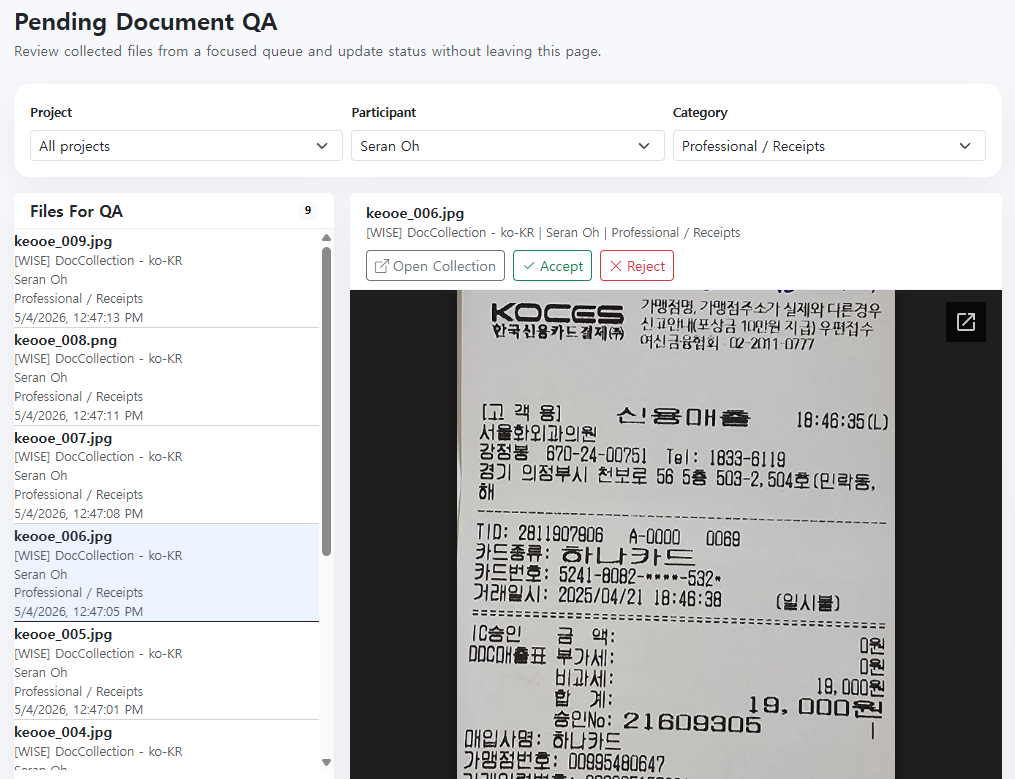
A secured workspace where participants access media assets entirely in-browser — no downloads, no data leakage. Invitees join via a personal workspace link and transcribe or annotate under project-level rules for max characters, CPS, and segment duration, with automatic violation detection and a full review control suite.
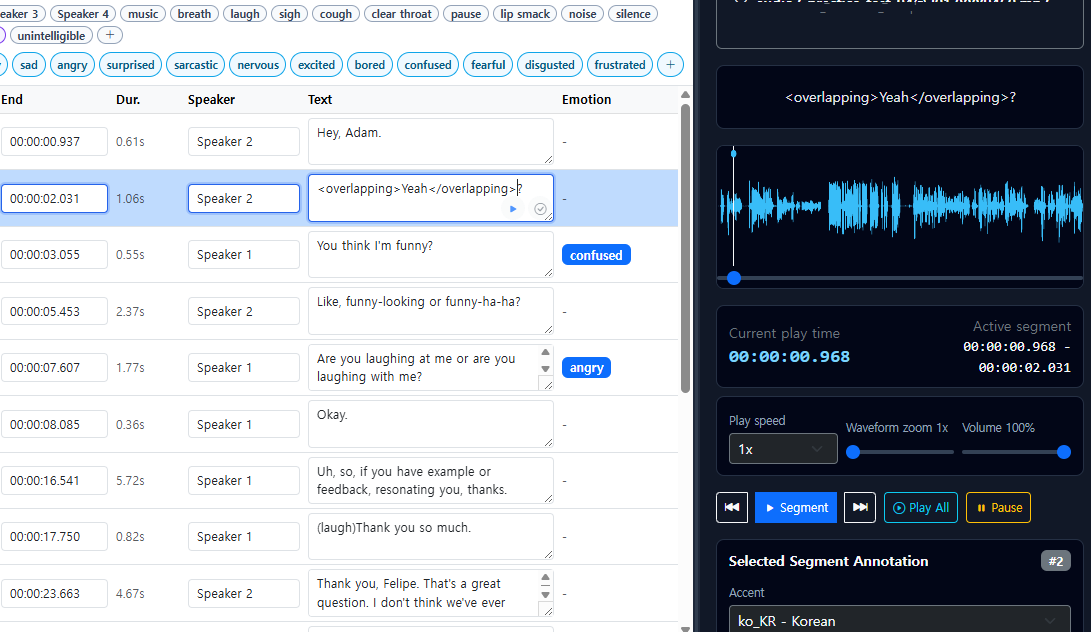
End-to-end operational control handling our entire HR pipeline, physical device logistics, and supervisor oversight. Features automated risk-based QA sampling to intelligently focus human review where it matters most, reducing cost without reducing coverage.